지난 포스팅(https://taeminator1.tistory.com/43)에 이어 이번 시간에는 Swift를 이용해 힙을 실제로 구현해 보겠다.
먼저 힙을 구성하는 노드(연결 리스트에서 사용한 노드와 구별하기 위해 Heap Node라고 이름을 지었다)를 구현해 주겠다.

연결 리스트에서 구현해 준 노드 클래스와 마찬가지로 제네릭을 이용해 다양한 타입에 대응되게 만들었다. 다만 연결 리스트의 노드와 달리 힙 노드는 노드 간에 값을 비교해야 하기 때문에 Comparable 프로토콜을 준수하여 구현하였다.
class HeapNode<T: Comparable>: Comparable {
var data: T
init(_ data: T) {
self.data = data
}
func getData() -> T {
return data
}
func setData(_ data: T) {
self.data = data
}
static func < (lhs: HeapNode<T>, rhs: HeapNode<T>) -> Bool {
return lhs.getData() < rhs.getData()
}
static func == (lhs: HeapNode<T>, rhs: HeapNode<T>) -> Bool {
return lhs.getData() == rhs.getData()
}
deinit {
print("Node with \(data) has been expired.")
}
}
이제 HeapNode클래스를 이용하여 Heap 클래스를 정의해 주면 된다.
(참고로 Heap을 구조체로 선언해 주어도 상관없다. 다만 다른 포스팅에서 구현한 Node와의 통일성을 위해 Class로 선언해 주었다. 구조체로 선언할 시에는 앞으로 나오는 코드를 살짝 변경해야 하지만 이번 포스팅에서 설명하지는 않겠다)

클래스 다이어그램을 살펴보면, 배열을 통해 HeapNode를 저장하였고, 다양 함수들이 존재한다. 여러 getter 함수가 존재하는데, 해당 함수는 삽입/삭제 연산 시에 해당 노드와 관련 있는 노드를 반환하기 위해 정의하였다. (isEmpty(), displayElements(), getCount() 함수는 간단하여 설명을 생략한다)
이제부터 본격적으로 실제 코드를 함께 살펴보자.
속성 중에서 count는 Heap 인스턴스에 있는 hNodes의 개수이다. 해당 값은 힙이 비어있는지 알려주거나 배열을 언제까지 순회할지 알려준다.
class Heap<Element: Comparable> {
var hNodes: [HeapNode<Element>] = []
var count: Int = 0 // hNodes의 원소의 개수
}
다음은 특정 인덱스에 있는 힙 노드의 부모 또는 자식 노드를 반환하는 getter를 정의하였다. 이전 포스팅에서 설명한 대로 배열과 완전 이진 탐색 트리의 관계를 고려하여 작성하였다. 각각의 노드는 부모 또는 자식 노드가 있을 수도 있고 없을 수도 있어 옵셔널을 반환하도록 하였다.
extension Heap {
func getParent(at index: Int) -> HeapNode<Element>? {
guard index > 0 && index < count else {
print("Index out of range")
return nil
}
return hNodes[(index - 1) / 2]
}
func getLeftChild(at index: Int) -> HeapNode<Element>? {
guard index >= 0 && index * 2 + 1 < count else {
print("Index out of range")
return nil
}
return hNodes[index * 2 + 1]
}
func getRightChild(at index: Int) -> HeapNode<Element>? {
guard index >= 0 && index * 2 + 2 < count else {
print("Index out of range")
return nil
}
return hNodes[index * 2 + 2]
}
}
힙 클래스에서 가장 중요한 연산 중 하나인 삽입 연산을 구현해 보자.
힙의 삽입 연산은 크게 세 단계로 나뉜다.
- 배열의 자리를 한 칸 늘려 해당 위치를 표시한다.
- 부모 노드가 존재한다면, 표시한 위치를 부모 노드의 위치로 바꾸고 해당 노드의 값과 삽입하고자 하는 노드의 값 중 큰 값으로 이전 위치의 노드 값을 설정한다.
- 변화가 없을 때까지 2 단계를 반복하며, 마지막 위치에 삽입하려는 노드의 값을 설정한다.
예를 들어 아래 왼쪽과 같은 힙이 있다고 가정하고, 값이 51인 노드를 삽입해 보자. 여기서 1단계인 자리를 한 칸 늘리고 해당 위치를 표시한다(빨간색 타원). hNodes에 삽입하기 원하는 노드를 이용해 배열의 크기를 증가시켰지만, 해당 노드의 값은 중요하지 않다.

그다음은 2단계의 반복이다. 표시한 노드의 부모 노드의 값인 24와 삽입하고자 하는 노드의 값인 51을 비교하는데, 51이 더 크므로 24를 표시한 노드의 값으로 설정하고 표시한 위치를 부모 노드(초록색 타원)로 바꾼다. 같은 방법으로 부모 노드의 값인 35와 삽입하려는 노드의 값 51을 비교하여 표시된 위치를 35로 설정하고 위치를 부모 노드(파란색 타원)로 바꾼다.

표시된 위치에서 더 이상의 부모 노드는 없으므로, 삽입하려는 값 51을 설정한다.

다음은 실제 구현이다. 여기서는 부모 노드가 존재하는 지의 여부를 index > 0으로, 두 값을 비교하는 부분을 data > getParent(at: index)!.getData()로 구현하였다.
extension Heap {
func insert(data: Element) {
var index = count
hNodes.append(HeapNode(data)) // hNodes의 자리만 늘리기 위한 목적
count += 1
while index > 0 && HeapNode(data) > getParent(at: index)! {
hNodes[index].setData(hNodes[(index - 1) / 2].getData())
index = (index - 1) / 2
}
hNodes[index].getData(key)
}
}
또 다른 핵심 연산인 삭제 연산을 구현해 보자. 삭제 연산 시에는 원하는 노드를 루트 노드로 갖는 트리 내에서 연산을 수행하게 된다. 만약 삭제를 원하는 노드가 전체 트리의 루트 노드라면(index의 값이 0이라면) 이는 우선순위 큐(Priority Queue)에서의 삭제 연산과 동일하다.
힙의 삭제 연산도 크게 세 단계로 나뉜다.
- 해당 인덱스에 해당하는 노드의 위치를 표시하고, 배열의 마지막 원소 삭제하고 반환한다.
- 표시한 노드의 자식 노드가 존재한다면, 표시한 자리를 자식 노드 중 큰 값으로 설정하고 해당 노드의 위치를 표시한다. 표시된 위치를 기준으로 이 과정을 반복한다.
- 변화가 없을 때까지 2 단계를 반복한다.
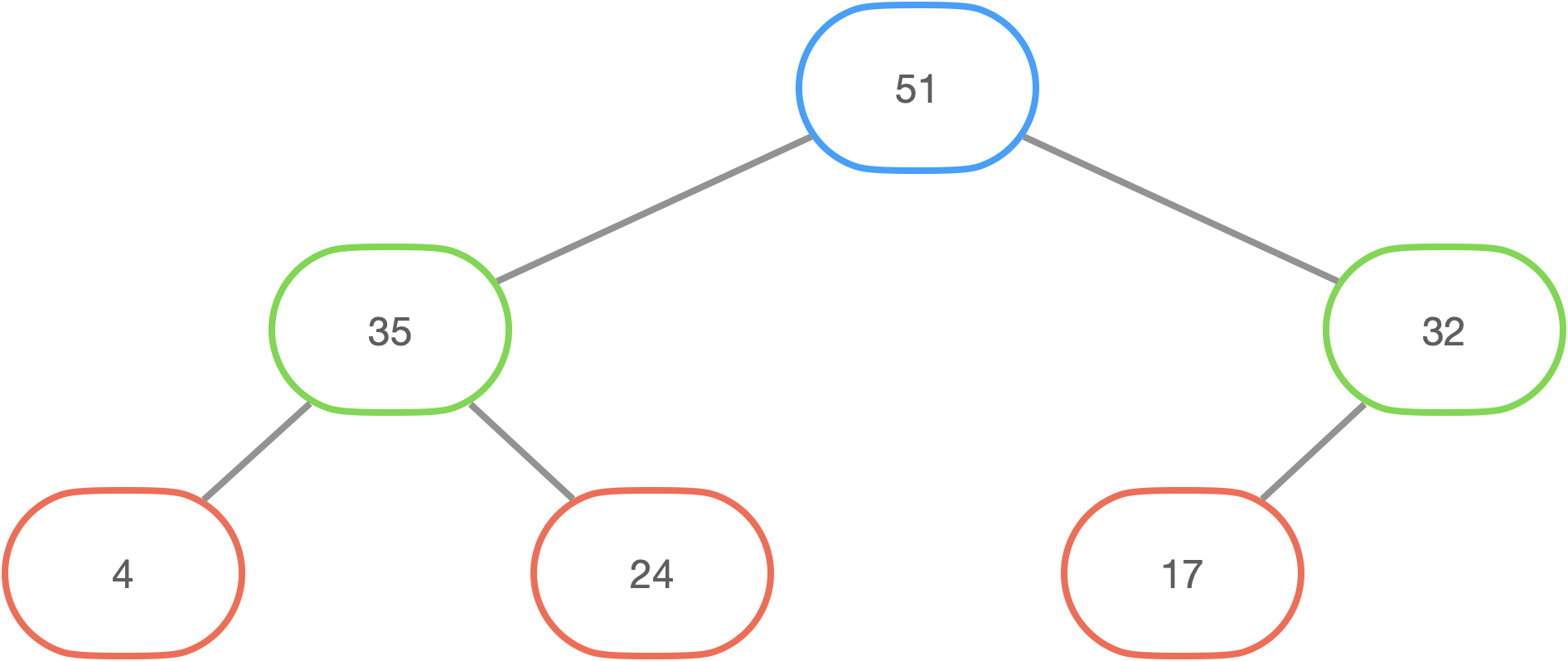
마찬가지로 예를 들어 살펴보자. 아래 그림과 같은 힙이 있다고 가정할 때, 53의 값을 갖는 노드(루트 노드)를 삭제해 보자(사실 노드의 값이 변하고 마지막 노드가 삭제되는 것이 맞는 표현이다).

1단계인 해당 인덱스에 해당하는 노드의 위치를 아래 왼쪽과 같이 표시(파란색 타원)하고 배열의 마지막 원소를 삭제하고 32라는 값을 반환받는다.

2단계로 32와 표시한 위치의 자식 노드 중 큰 값과 비교하여 큰 51을 표시한 위치의 값으로 설정하고 해당 자식 노드의 위치를 위의 오른쪽과 같이 표시(초록색 타원)한다. 또 32와 표시한 위치의 자식 노드 중 큰 값(여기서는 자식 노드가 하나밖에 없다)을 비교하여 큰 값을 해당 표시한 위치에 값으로 설정한다.
다음은 실제 구현이다. 초기에 부모 인덱스(pIndex)는 삭제하려는 위치로 설정하고 자식 인덱스(cIndex)는 왼쪽 자식 노드의 위치로 설정한다. 그리고 난 뒤에 왼쪽 자식 노드와 형제 관계인 오른쪽 자식 노드와 비교하여 어떤 인덱스를 자식 인덱스로 할지 최종 결정한다. 결정된 인덱스에 값을 표시된 위치(부모 인덱스가 가리키는 노드의 값)로 설정하고 부모 인덱스는 자식 인덱스로, 자식 인덱스는 다시 자식 인덱스로 설정하여 이 과정을 반복한다.
extension Heap {
@discardableResult func remove(at index: Int = 0) -> HeapNode<Element>? {
guard index >= 0 && index < count else {
return nil
}
let result: HeapNode<Element> = hNodes[index]
count -= 1
if count == 0 { return result }
let lastHeapNode: HeapNode<Element> = hNodes.removeLast()
var pIndex: Int = index // parent index
var cIndex: Int = pIndex * 2 + 1 // child index
while cIndex < count {
if cIndex < count - 1 && getLeftChild(at: pIndex)! < getRightChild(at: pIndex)! {
cIndex += 1
}
if lastHeapNode >= hNodes[cIndex] { break }
hNodes[pIndex] = hNodes[cIndex]
pIndex = cIndex
cIndex = cIndex * 2 + 1
}
hNodes[pIndex] = lastHeapNode
return result
}
}이제 실제로 잘 동작하는지 확인해 보자. 먼저 다음과 같이 Heap 클래스의 인스턴스를 생성하고 데이터를 순서대로 넣어 준다. 그러면 다음과 같이 반정렬 상태를 유지하면서 데이터가 삽입되는 것을 알 수 있다. 그리고 마지막 출력에서 알 수 있듯이 가장 첫 번째 힙 노드가 가장 큰 값을 같는다.

다음은 삭제 연산을 실행할 텐데, 51를 값으로 갖는 힙 노드(세 번째 힙 노드)를 삭제해 보겠다. 그러면 다음가 같이 51의 값을 갖는 노드가 제거되고 반정렬 상태를 유지하기 위해 재 정렬된다.

다음 포스팅에서는 다양한 종류의 힙을 어떻게 구현하면 좋을지에 대해 포스팅하겠다.
'Computer Science > 데이터 구조' 카테고리의 다른 글
| [Swift] Heap을 이용한 Priority Queue 구현 (0) | 2021.06.05 |
|---|---|
| [Swift] Array를 이용한 Heap 구현 3 - 함수형 프로그래밍 (0) | 2021.06.04 |
| [Swift] Array를 이용한 Heap 구현 1 - 개요 (0) | 2021.06.03 |
| 트리 (0) | 2021.06.02 |
| [Swift] Linked List를 이용한 List 구현 (0) | 2021.06.01 |



