트랜지스터는 일종의 스위치이다. 스위치는 off와 on의 두 가지 상태를 나타낼 수 있으며, 이러한 각각의 상태를 0과 1로 치환하여 모으면 이진수로 나타낼 수 있다. 컴퓨터는 자신을 구성하는 트랜지스터를 이용해 이진수로 데이터를 저장한다.
하지만 이진수는 사람이 바로 이해하고 사용하기 힘들기 때문에, 우리가 일반적으로 사용하는 문자들(숫자, 글자, 기호 등)을 컴퓨터가 이해할 수 있는 이진수로 변환하는 작업이 필요하다. 이렇듯 우리가 입력한 문자열을 이진수의 모임으로 변환하는 작업을 인코딩(encoding)이라고 하며, 반대로 이진수의 모임을 문자열로 변환하는 작업을 디코딩(decoding)이라고 한다.
인코딩을 하기 위해서는 각각의 이진수와 문자들을 대응시킨 규칙이 필요하다. 이러한 규칙에는 대표적으로 아스키(ASCII)와 유니코드(Unicode)가 있다.
아스키(ASCII: American Standard Code for Information Interchange)는 각각 7bit로 구성된 이진수에 대응되는 문자들이다. 7bit는 십진수로 127이기 때문에, 아스키는 0부터 127까지의 숫자(128개)에 해당하는 문자들인 셈이다. 대응되는 수에 한계를 느껴 앞에 1비트를 추가하여 확장 아스키(extended ASCII)가 만들어졌다. 하지만 256(8bit이므로 256가지의 문자를 나타낼 수 있다) 가지의 문자도 전 세계에서 사용되는 다양한 문자를 저장하기에는 턱없이 부족했다.
그래서 등장한 것이 바로 유니코드다. 유니코드는 2byte로 이루어진 이진수에 대응되는 문자들로, 10진수로 0부터 65535까지의 숫자(65536개)를 나타낼 수 있다. 65536가지의 숫자는 숫자와 알파벳뿐만 아니라, 한글, 한자 등 세상에 존재하는 다양한 문자들을 모두 대응시키기에 충분하다.
이러한 유니코드를 기반으로 문자와 이진수를 1대 1 대응시켜 인코딩할 수 있지만, 그렇게 하면 문제가 발생한다. 이전에 생성된 아스키 기반의 인코딩 된 데이터를 디코딩할 경우, 아스키가 7비트의 이진수를 대변하기 때문에 2 바이트로 구성된 이진수를 대변하는 유니코드를 이용하여 디코딩하는 것과 차이를 일으킨다.
이런 문제는 현재 가장 널리 사용되는 인코딩 방식 중 하나인 UTF-8을 사용하여 해결이 가능하다. UTF-8은 길이가 변경되어 저장할 수 있는 인코딩 방식(가변 길이 문자 인코딩 방식)이다. 이전에 널리 사용되던 아스키는 1바이트로 나타내고(MSB가 0으로 고정하여 7비트의 아스키를 그대로 표현 가능), 이외에 데이터는 2~4바이트로 나타내어 인코딩한다.
각각의 유니코드에 대해 1바이트부터 4바이트까지 다르게 부여하는데, 각각의 바이트의 상위 비트에 일정한 규칙을 부여하여, 디코딩 시에 바이트 별로 데이터가 혼동될 여지를 없앴다. 아래 유니코드에 대응하는 십진수에 대해 각 바이트를 아래와 같은 규칙으로 인코딩하게 된다.
(4 바이트 표현은 거의 사용되지 않아 생략하였다)
- 0~127: 0xxxxxxx
- 128~2047: 110xxxxx 10xxxxxx
- 2048~65535: 1110xxxx 10xxxxxx 10xxxxxx
예를 들어 각각의 아스키에 해당하는 이진수는 1바이트로 이루어져 있는데, MSB를 0으로 고정하고 7비트로 나타내기 때문에, 다른 바이트와 혼동될 일이 전혀 없다. 왜냐하면 아스키를 제외한 모든 문자들에 해당하는 이진수는 각각의 바이트가 모두 1로 시작하기 때문이다.
이러한 UTF-8을 이용하면 이전에 사용하던 아스키들은 물론이고 아스키를 제외한 유니코드들까지도 이진수로 표현이 가능하다.
맥에서 UTF-8을 이용하여 데이터를 인코딩하는 것을 쉽게 찾아볼 수 있다.
TextEdit를 열어, New Document를 클릭하여 새로운 문서를 연다. 그다음 아래와 같이 Format 탭에서 Make Plain Text를 선택하면, .txt 형식으로 문서를 편집할 수 있게 된다.

그리고 샘플 문자를 몇 개 아래와 같이 입력하고,
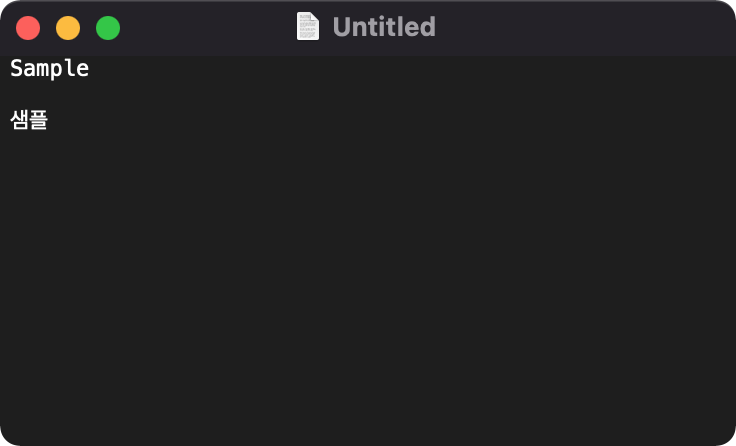
저장하면 다음과 같이 인코딩 방식을 선택할 수 있다. 이번 시간에 알아본 Unicode (UTF-8)을 선택하고 Save를 눌러 저장한다.
그리고 저장된 파일에서 마우스 오른쪽 버튼을 누른 뒤 Get Info를 클릭하면, 아래와 같이 해당 파일에 대한 정보를 확인할 수 있다.


다른 정보는 무시하고, 오른쪽 상단에 보이는 저장 용량을 주의 깊게 살펴보자.
앞서 "S", "a", "m", "p", "l", "e"이라는 6개의 알파벳과 줄 바꿈 두 번, 그리고 "샘", "플"이라는 한글 2 글자를 입력하였다. 유니코드는 모든 문자를 2 바이트의 이진수로 나타내기 때문에, 총 10 글자이므로 20 바이트의 저장 공간을 차지해야 한다. 하지만 실제로는 14 바이트를 차지하는데, 그 이유는 UTF-8 인코딩에서는 아스키와 아스키 이외의 유니코드에 대해 서로 다른 바이트를 부여하기 때문이다.
UTF-8 인코딩에서는 알파벳과 줄 바꿈은 각각 1 바이트를 차지하고, 한글은 각각 3 바이트를 차지한다.
따라서 14(8 x 1 + 2 x 3) 바이트의 저장 공간을 차지하게 된다.
참고 사이트